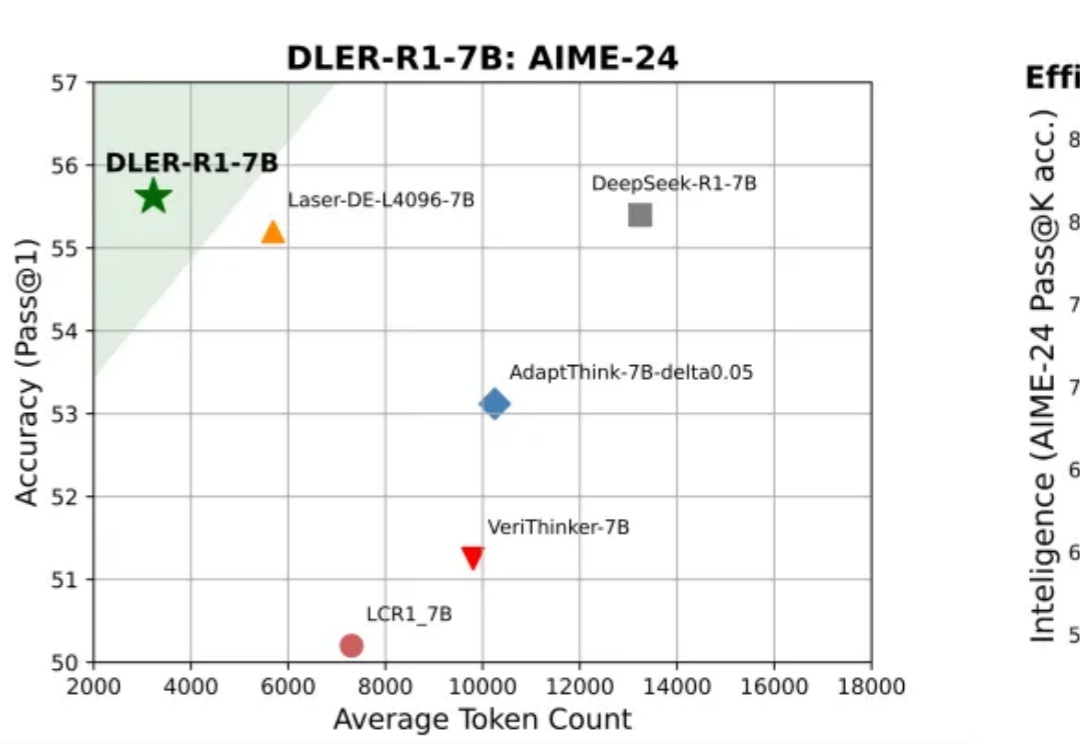
英伟达帮你省钱,让大模型推理「短而精」,速度快5倍
英伟达帮你省钱,让大模型推理「短而精」,速度快5倍大模型推理到底要不要「长篇大论」?过去一年,OpenAI o 系列、DeepSeek-R1、Qwen 等一系列推理模型,把「长链思维」玩到极致:答案更准了,但代价是推理链越来越长、Token 消耗爆炸、响应速度骤降。
来自主题: AI技术研报
7389 点击 2025-11-04 16:09
 搜索
搜索
大模型推理到底要不要「长篇大论」?过去一年,OpenAI o 系列、DeepSeek-R1、Qwen 等一系列推理模型,把「长链思维」玩到极致:答案更准了,但代价是推理链越来越长、Token 消耗爆炸、响应速度骤降。

就在今天,OpenAI 与 AWS 官宣建立多年的战略合作伙伴关系。OpenAI 将立即并持续获得 AWS 世界级的基础设施支持,以运行其先进的 AI 工作负载。 AWS 将向 OpenAI 提供配备数十万颗芯片的 Amazon EC2 UltraServers(计算服务器),并具备将计算规模扩展至数千万个 CPU 的能力,以支持其先进的生成式 AI 任务

OpenAI Atlas、Perplexity Comet等AI浏览器的推出,虽提升了网页自动化效率,却也使智能爬虫威胁加剧。南洋理工大学团队研发的WebCloak,创新性地混淆网页结构与语义,打破爬虫技术依赖,为数据安全筑起轻量高效防线,助力抵御新型智能攻击,守护网络安全。

过去一周,我把主流 AI 浏览器都体验了个遍。 OpenAI 的 Atlas、Perplexity 的 Comet、Browser Company 的 Dia,再加上 Edge Copilot,市面上最火的 AI 浏览器,各有各的亮点,也各有各的坑。浏览器的未来长啥样?这些产品给出了完全不同的答案。
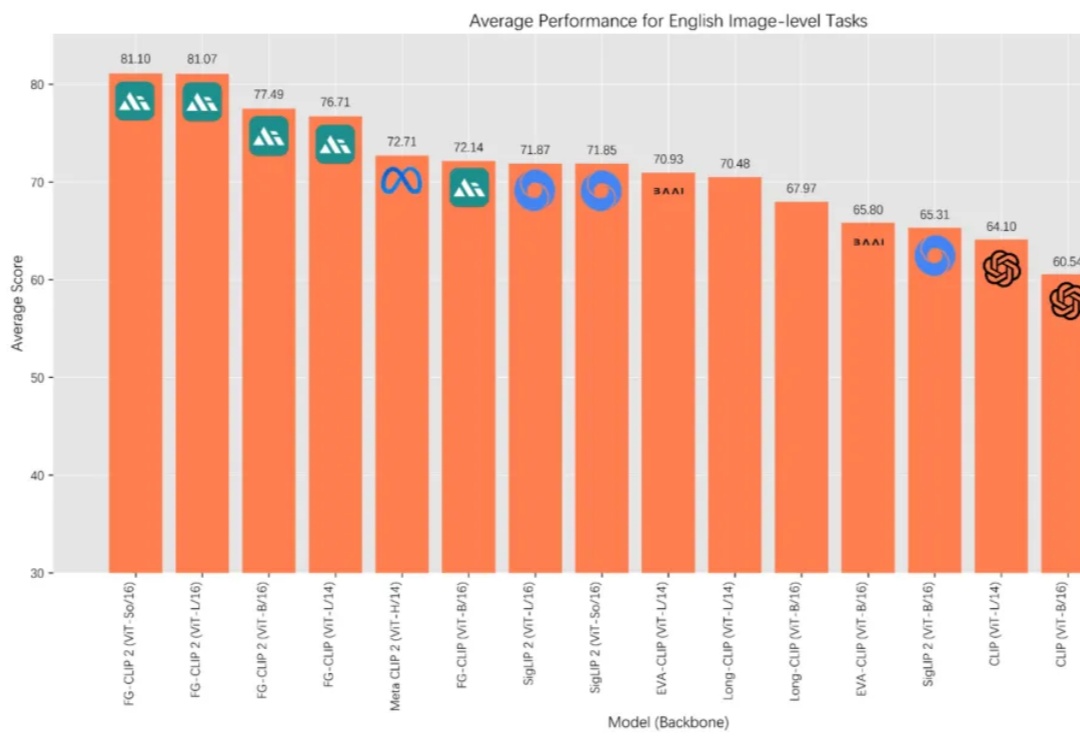
在 AI 多模态的发展历程中,OpenAI 的 CLIP 让机器第一次具备了“看懂”图像与文字的能力,为跨模态学习奠定了基础。如今,来自 360 人工智能研究院冷大炜团队的 FG-CLIP 2 正式发布并开源,在中英文双语任务上全面超越 MetaCLIP 2 与 SigLIP 2,并通过新的细粒度对齐范式,补足了第一代模型在细节理解上的不足。

最大的时代红利,属于今年四季度发布的中美两大明星产品,OpenAI 的 Sora 2 与阿里的 Wan2.5-Preview。其中,Sora 2 的登场堪称一场教科书级的营销战役。熟悉的邀请码机制再次奏效,用户为了获得一个入场券除了需要购买 GPT 的会员之外,甚至还在二手平台再花几十美金购买邀请码。更绝的是,它把自己变成了一个 AI 版抖音,
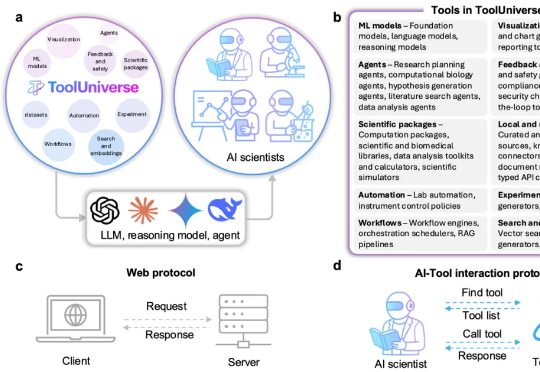
近日,OpenAI 宣称要在 2028 年实现让 AI 完全自主做研究,一下子又把焦点聚在了AI 科学家。 过去,AI 只是作为“助理”辅助研究者们进行科学研究。现在,美国哈佛大学与美国麻省理工学院联

刚刚,OpenAI推出了使用GPT-5寻找和修复安全漏洞的智能体Aardvark。目前,Aardvark还处于beta测试阶段。OpenAI称,Aardvark开创了「防御者优先」的新范式:作为自主安全研究智能体,随代码不断演化,为团队提供持续保护(continuous protection)。
尽管今天还有 Sora 角色客串功能和 GPT-5 查找和修复安全漏洞智能体的消息,但本文的重点是深扒 Atlas 背后的「灵魂」—— OWL 架构。看看 OpenAI 究竟是如何驯服 Chromium,把它从浏览器「换皮」玩成了「架构重组」的。

今年三月,Liam Fedus 在推特上宣布离开 OpenAI。这条推文的影响力超出了所有人的预期——硅谷的风投们几乎是立刻行动起来,争相联系这位 ChatGPT 最初小团队的核心成员、曾领导 OpenAI 关键的后训练部门的研究者,他的离职甚至一度引发了一场“反向竞标”。